The statistics of telephone voice traffic are well-understood. Years of measurement and study led to the development of a mathematical theory, queueing theory. The Poisson distribution (similar to the normal distribution) describes the statistics of voice traffic. Voice traffic is nearly homogeneous, of constant (low) information rate, and typical calls last a fairly long time (very long by computer standards). Because of the low information rate per call, many concurrent voice calls can be multiplexed. They can share a common circuit because the circuit's information capacity greatly exceeds the requirements of a single call. Voice traffic is controlled by circuit switching: routers keep track of the connections from link to link, so each message is uninterrupted. If I call TicketMaster in Chicago, a circuit is established between here and there, and it stays open until I've bought my Tori Amos tickets.
Data traffic is not at all like voice traffic. For one thing, it is MUCH more variable, both in duration and in information rate. Data is broken into autonomous packets that are transmitted independently of one another. The control is by packet-switching: the routers look at the source and the destination, and find the best path for each packet, using all available bandwidth. If I access the TicketMaster website, my message is broken up into a collection of little packets that travel from here to Chicago much as a swarm of bees might - the same general direction, but individual paths can be unrelated.
In the early days of the Internet, the late 70s and early 80s, designers assumed voice traffic statistics would work for data traffic. Few measurements were made, and the early days of the net were filled with the digital equivalent of the busy signal. Because there is no global routing of packet traffic, it can happen that packets can arrive at busy links at rates exceeding the capacity of the link. The design solution was to equip each link with a buffer for excess packets. When the downstream traffic cleared, packets in the buffer were sent on their way. Unfortunately, the fluctuations in data traffic are much larger than those of voice traffic. Early buffers were occasionally terribly inadequate, and buffered packets often were lost.
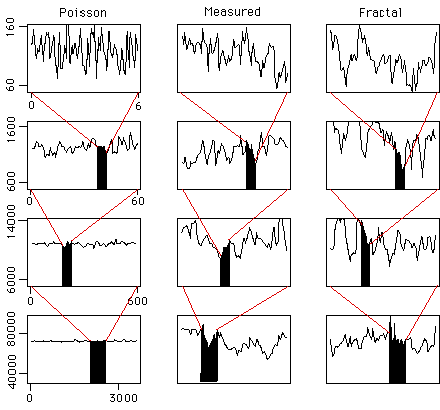
Willinger and Paxson presented a study of the statistics of internet traffic. They compared real data - an hour of net traffic at a large corporation (middle), with a Poisson model (left) of the same mean and standard deviation as the data, and with a fractal model (right) of the same characteristics. Pictures in the top row are 6 seconds in 100 msec intervals. In the second row, these are compressed into the small black regions; the whole graph is now packets per second over a 60 sec range. Third is packets per 10 sec, over 10 minute intervals. Fourth is packets per minute over 1 hr intervals.
|
Over longer time scales, the Poisson model flattens out, while the data and the fractal model do not. In fact, the match of the latter two is quite good. The immediate design lesson is to make much larger buffers to accommodate fluctuations across many timescales.